CODA – Bioinformatics

Bioinformatics analysis is provided for users with own data and the scope depends on users’ requirements. Services ranging from sequencing analysis, protein structure prediction, protein-protein interaction, and gene network analysis to the development of biological database from various omics data. There are four major components in CODA-bioinformatics platform involving sequence-based analysis, structural bioinformatics, network analysis and development of biological database.
1.Sequence-based analysis
In this workflow, bibliomic data that involve information curated from scientific literatures and other databases as well as experimental data are collected, stored and analyzed. Physicochemical prediction and profile analysis from the protein sequence are calculated using various tools such as ProtParam, InterProScan, Pfam and SMART. Glycosylation and phosphorylation sites are also predicted using NetNGlyc and NetPhos respectively. Sequence homology search analysis will be also carried out using appropriate blast programs. Selected sequences from blast analysis will be used for multiple sequence alignment to determine the important conserved regions within the group of proteins of interest. Phylogenetic analysis will be then carried out to see the evolutionary relationships between the protein sequences.

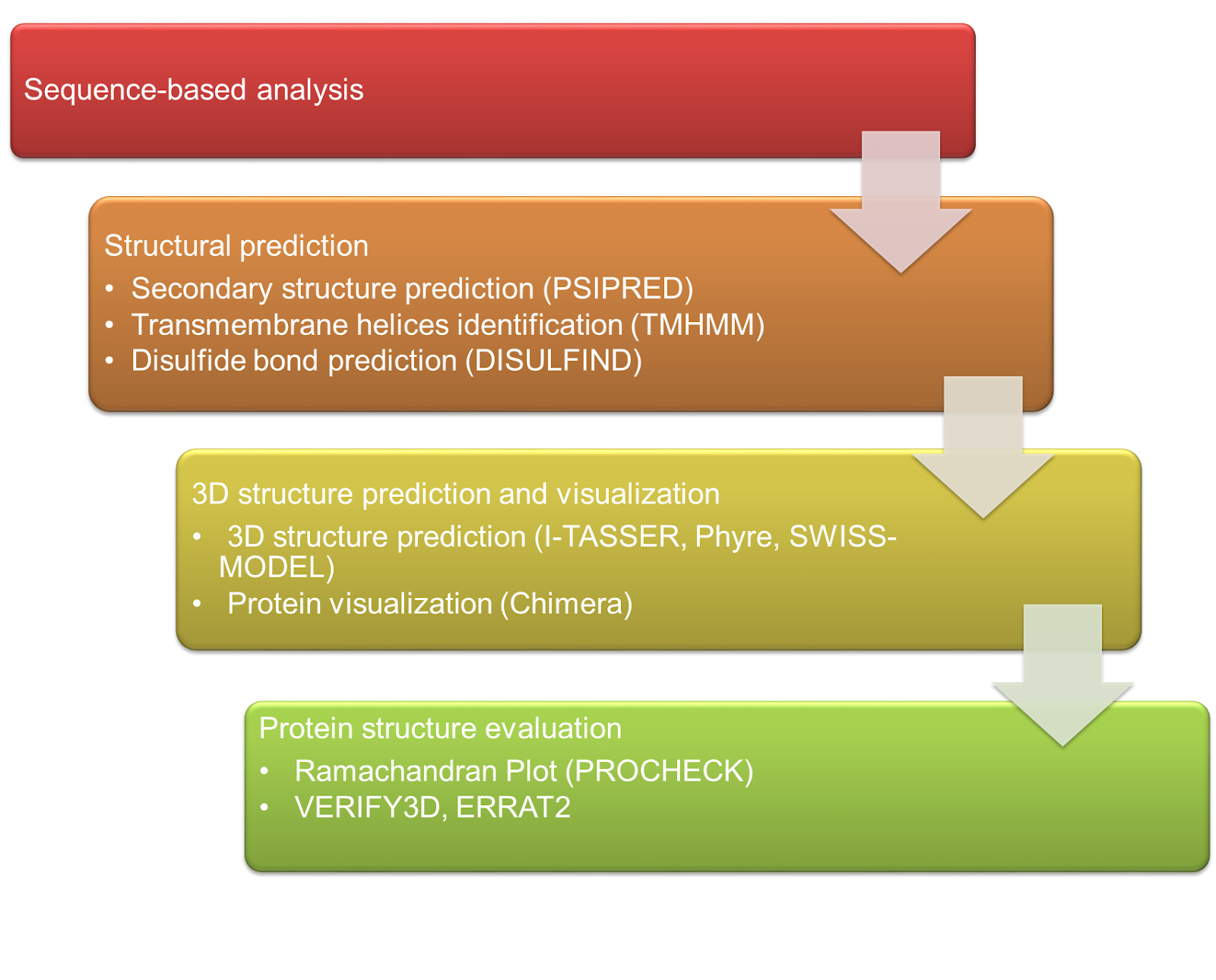
2. Structural Bioinformatics
The first step in structural bioinformatics is usually sequence-based analysis to investigate and annotate the protein sequence of interest. Next, structural prediction will be done to uncover the secondary structure, transmembrane helices and disulphide bond properties available in the protein sequence using PSIPRED, TMHMM and DISULFIND respectively. 3D structure will be constructed using possible tools such as I-TASSER, Phyre or SWISS-MODEL. The 3D structure protein will be evaluated using several program tools namely PROCHECK, VERIFY3D and ERRAT2.
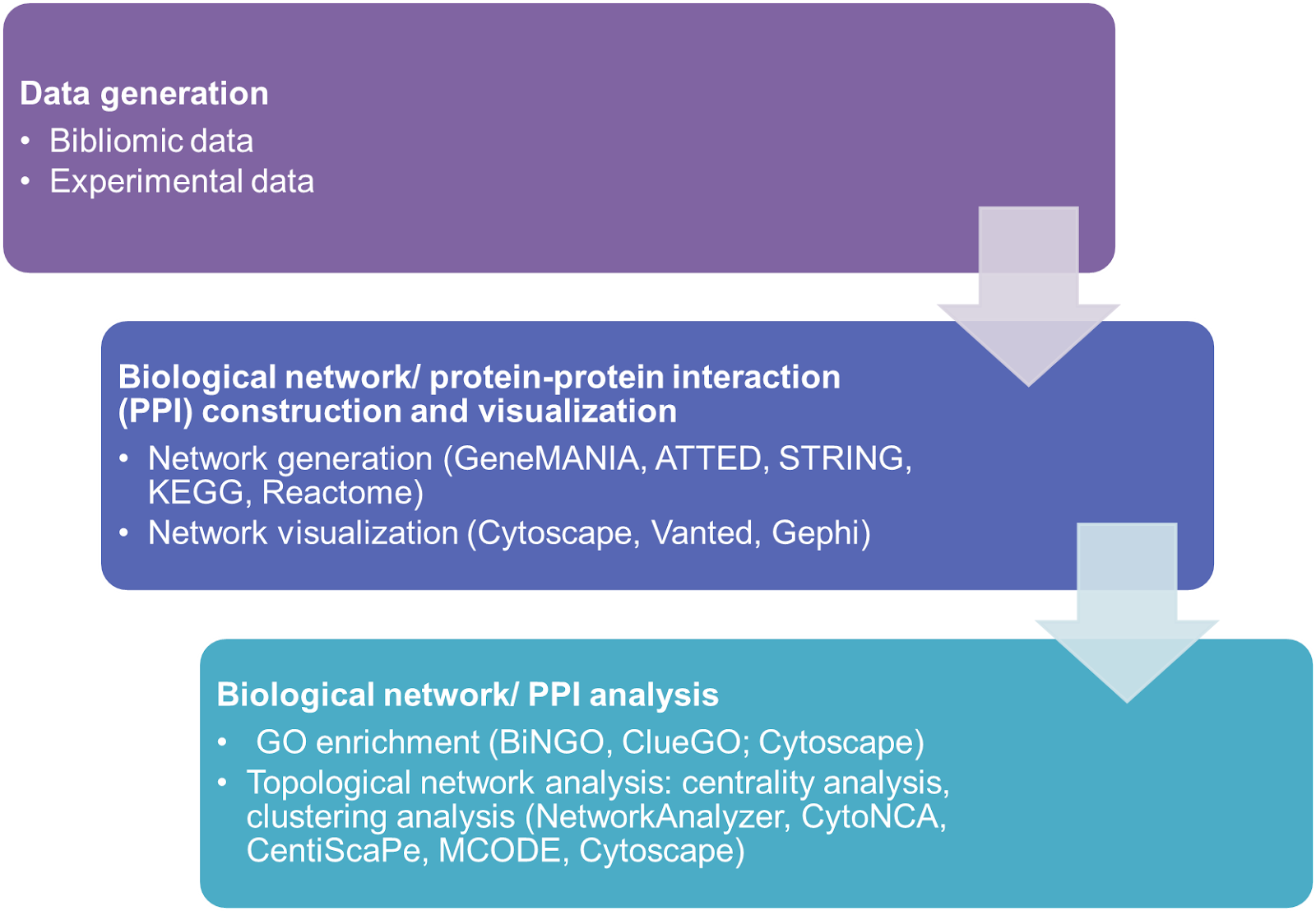
3.Network analysis
Bibliomic and experimental data are usually used as query in constructing a protein-protein interaction (PPI) and biological network. There are several biological network databases that are available such as GeneMANIA, ATTED, STRING, KEGG and Reactome. All of this network data can be visualized using Cytoscape as well as other visualization tools such as Vanted and Gephi. The constructed network will be then analysed for gene ontology enrichment and topological analysis using a number of applications in Cytoscape.
4.Development of biological database
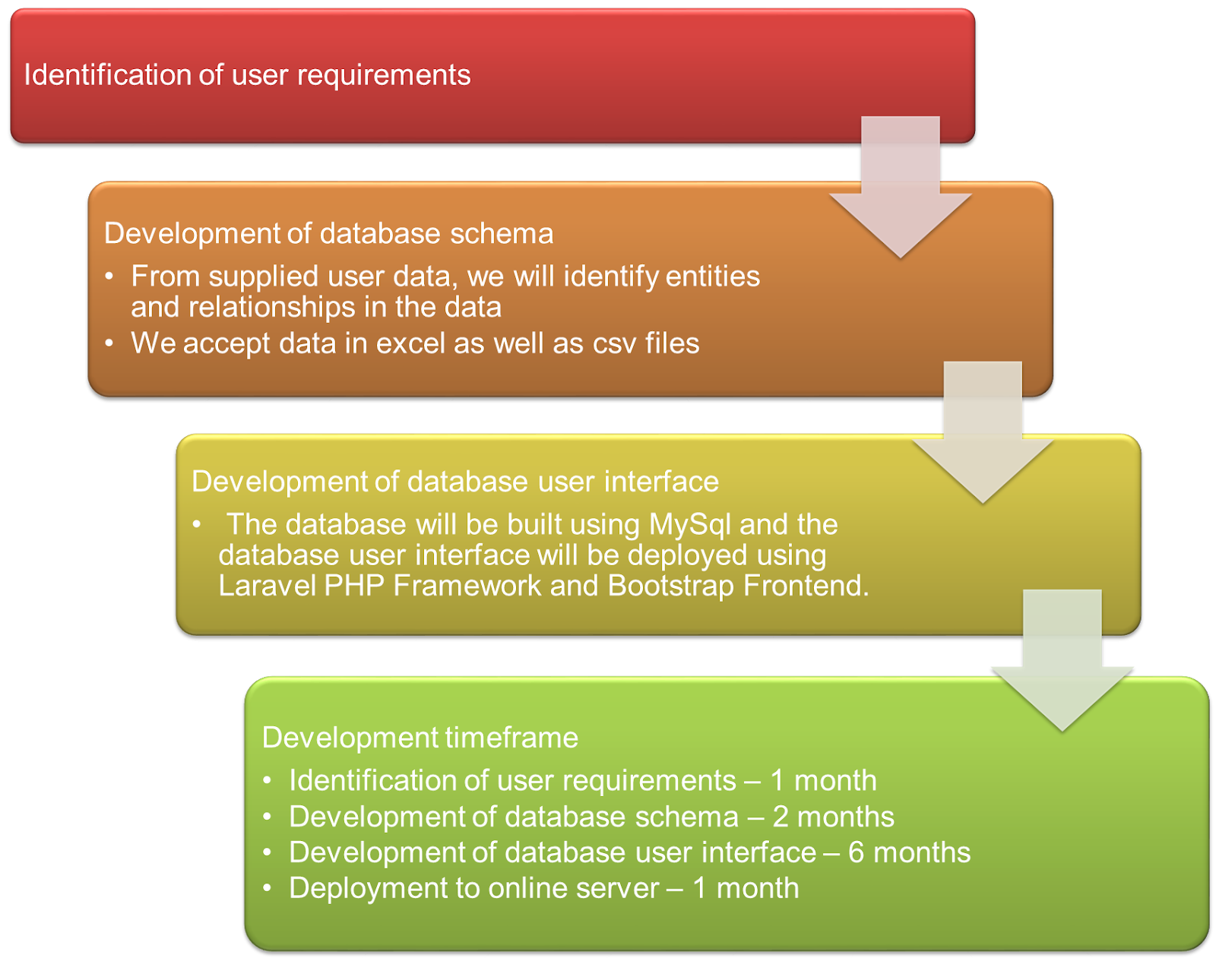
Identification of user requirements
The user needs to list all features that is needed in the database product. If the user does not have a design for the database ready, we will start by proposing the new database to use the same framework as our existing databases. Our databases have these features:
- Information pages
- Search and advance search function
- Browse function
- Dashboard/statistics page
- Auto adjust of page layout depending on screen resolution
- Mobile site included along the desktop site
- Modern design through the use of themes
Development of database schema and user interface
From supplied user data, we will identify entities and relationships in the data. We accept data in excel as well as csv files. The database schema will reflect the user’s data as well as the user requirements towards the database’s user interface. We will apply database normalization onto the draft schema to generate the final database schema. The database will be built using MySql and the database user interface will be deployed using Laravel PHP Framework and Bootstrap Frontend. The code will be modular thus each feature of the database will have their own code for easier development in the future of needed.
WHAT DO WE OFFER
We offer bioinformatics consultation and services customized to the needs of the project and available data. Guidelines on the estimated pricing as below. We are also open to other bioinformatics analysis requests other than the ones listed. Do contact us for any inquiries.
Overview of services
| Data analysis and bioinformatics | – Sequence-based analysis – Structural bioinformatics – Network analysis – Development of biological database |
PRICING DETAILS
| TYPE OF ANALYSIS | CHARGES |
| Sequence analysis | RM 200 / 1,000 sequence |
| Analysis of protein structure | RM 150/protein |
| Analysis of biological pathways | RM 500/1,000 sequence |
| Database development | Database scheme – starting from RM 5,000 SQL Database (data in phpMyAdmin) – starting from RM 2,000 (until 10 entity) Database user interface (PHP controller & frontend) – starting from RM 8,000 (until 10 entity) Database server and maintenance – starting from RM 2,000 (per annum) Database migration – RM 2,000 |
ACHIEVEMENTS
PERSON IN CHARGE

Ts. Dr. Nor Azlan Nor Muhammad
University Lecturer DS13
+603 8921 4550
norazlannm@ukm.edu.my
NGS Informatics and Biological Database Development

University Lecturer DS13
sarahani@ukm.edu.my
Bioinformatics and Computational Systems Biology